
La historia de la Inteligencia Artificial (IA) también es la historia del Machine Learning (ML) y del Deep Learning (DL). Es decir, al hablar de IA tenemos que hablar sobre sus subcampos, el ML y DL, que se desarrollaron a la par y poco a poco fueron ampliando sus áreas de especialidad.
Aunque parezca un tema difícil de abordar, hay que entender que la historia de la Inteligencia Artificial no es del todo lineal. A lo largo de los años ha habido grandes descubrimientos y también los llamados “inviernos de la IA”.
En este artículo, cubriremos de manera breve los eventos más sobresalientes de la prehistoria, historia y revolución de la Inteligencia Artificial, además del inicio y desarrollo del Machine Learning o aprendizaje automático, así como del Deep Learning o también conocido como aprendizaje profundo.
Tabla de contenidos
- Prehistoria de la Inteligencia Artificial: 1700 - 1900
- Comienzo de la era computacional: 1900 – 1950
- Comienzo de la Inteligencia Artificial: 1950 – 2000
- Evolución de la Inteligencia Artificial: 2000 - 2023
- Historia del Machine Learning
- Historia del Deep Learning
Prehistoria de la Inteligencia Artificial: 1700 - 1900
3 PERSONAJES IMPORTANTES DE LA PREHISTORIA DE LA IA
1600 - 1850

1623: Wilhelm Schickard inventa la calculadora
Wilhelm Schickard fue un destacado profesor, matemático, teólogo y cartógrafo alemán. Wilhelm inventó varias máquinas para diversos fines, pero sus aportaciones más destacadas fueron la primera calculadora mecánica y una máquina para aprender la gramática del hebreo.
En 1623, Wilhelm Schickard creó un artefacto que le permitía realizar operaciones aritméticas de forma completamente mecánica: lo llamó el reloj calculador. Su funcionamiento se basaba en varillas y engranajes que mecanizaban las operaciones que antes se realizaban de forma manual.
1822: Charles Babbage construye la calculadora mecánica
Es considerado como el padre de las impresoras modernas y pionero de la informática.
En 1822, Babbage fue capaz de desarrollar y diseñar parcialmente una calculadora mecánica capaz de realizar cálculos en tablas de funciones numéricas por el método de diferencias además de diseñar la máquina analítica para ejecutar programas de tabulación o computación. Dentro de sus invenciones también está la máquina diferencial.
Posteriormente, Babbage trabajó con Ada Lovelace para traducir su escrito al italiano sobre la máquina analítica. Su relación ayudaría a cimentar los principios de lo que sería la inteligencia artificial.
1830: Ada Lovelace la primera programadora
La matemática británica Ada Lovelace desarrolló aportaciones que aún tienen un gran impacto en la actualidad, como el desarrollo del primer algoritmo junto con Charles Babbage.
Otra aportación importante de Lovelace fue el concepto de la máquina universal. Creó un artefacto que en teoría se podía programar y reprogramar para realizar diversas tareas sin limitarse al cálculo matemático como el procesamiento de símbolos, palabras e incluso música.
Comienzo de la era computacional: 1900 – 1950
3 EVENTOS QUE MARCARON EL INICIO DE LA ERA COMPUTACIONAL 1900-1950

1924: Creación de IBM
Fundada en 1911, originalmente era una compañía que desarrollaba máquinas para contar tarjetas perforadas. Debido a su éxito, y para reflejar el crecimiento internacional de la empresa, el nombre de la compañía se cambió a International Business Machines Corp. o IBM en 1924.
Sus inicios en el negocio los llevaría al ser líderes en soluciones de software, hardware y servicios que han marcado el avance tecnológico de esta era.
La organización ha conseguido adaptarse a los cambios tecnológicos del mercado para crear soluciones innovadoras a lo largo de los años.
1936: Turing Machine
La máquina de Turing fue creada en 1936 por Alan Turing, conocido como el padre de la Inteligencia Artificial.
Creó un modelo computacional capaz de almacenar y procesar información virtualmente, el cual marcó la historia de la informática y ha sido considerado como el origen de las computadoras, teléfonos móviles, tabletas y otras tecnologías actuales.
Este modelo computacional puede ser adaptado para simular la lógica de cualquier algoritmo. Su creación demostró que algunas de estas máquinas de Turing serían capaces de realizar cualquier cálculo matemático si fuera representable por un algoritmo.
1943: Primera computadora digital funcional ENIAC
El proyecto Electronic Numerical Integrator And Computer, ENIAC, se creó en 1943 por los estadounidenses John William Mauchly y John Presper Eckert. Se ideó con fines militares, pero no se terminó de construir hasta 1945 y se presentó al público en 1946, siendo utilizada para investigaciones científicas.
La máquina pesaba 27 toneladas, medía 167 metros cuadrados y constaba de 17,468 tubos. Era programable para realizar cualquier tipo de cálculo numérico, no tenía ningún sistema operativo ni programas almacenados y solamente guardaba los números que empleaba en sus operaciones.
Comienzo de la Inteligencia Artificial: 1950s – 2000
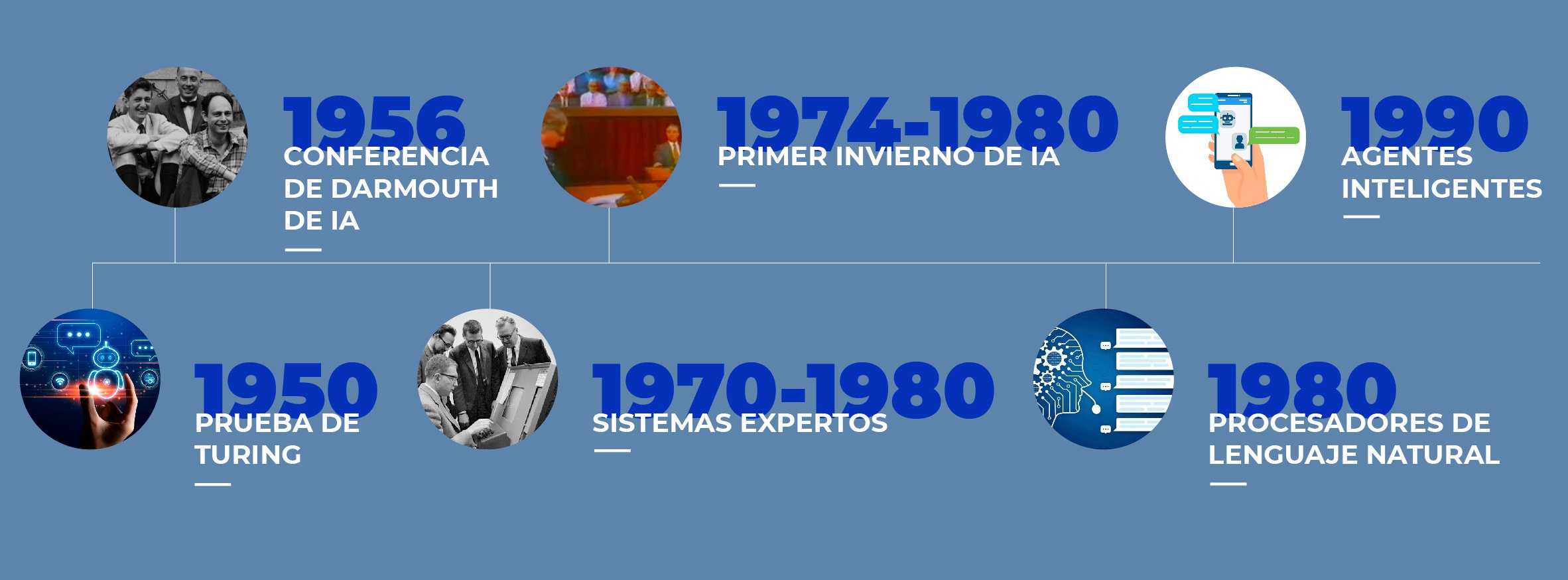
1950: Prueba de Turing
El test de Turing fue desarrollado por Alan Turing. El objetivo de esta prueba es determinar si la Inteligencia Artificial puede imitar las respuestas humanas.
Consiste en que el ser humano mantenga una conversación con una computadora y otra persona, pero sin saber quién de los dos conversadores es realmente una máquina. Es por eso que la persona hace preguntas al chatbot y a otra persona, y en caso de no distinguir al humano de la máquina, la computadora habrá pasado con éxito la prueba de Turing.
1956: Primera conferencia en Darmouth College sobre Inteligencia Artificial
En el verano de 1956, se realizó la primera conferencia en Dartmouth College sobre Inteligencia Artificial, organizada por Marvin Minsky, John McCarthy y Claude Shanon.
Este evento importante fue el punto de partida de la Inteligencia Artificial, ya que se usó este término por primera vez y se determinó que en 25 años los ordenadores harían todo el trabajo que el ser humano realizaba en ese entonces. Además, se discutió la lógica teórica, considerada como el primer programa de Inteligencia Artificial que resolvía problemas de búsqueda heurística.
1974-1980: Primer invierno de IA
El término “invierno de la Inteligencia Artificial” está relacionado con el declive en el interés, investigación e inversión en el campo de esta tecnología.
Comenzó cuando los investigadores de la IA tenían dos limitaciones básicas: poca memoria y rapidez en los procesos, la cual es mínima en comparación con la tecnología que existe en esta década.
Este periodo empezó después de los primeros intentos para crear sistemas de traducción automática, los cuales se usaron en la guerra fría, y terminó con la introducción de los sistemas expertos que fueron adaptados por cientos de organizaciones alrededor del mundo.
1970-1980: Sistemas expertos
Estos sistemas tuvieron gran popularidad en la década de los 70. Utilizaban conocimiento de expertos para crear un programa en el que un usuario realiza una pregunta al sistema para recibir una respuesta y se cataloga como útil o no.
El software utiliza un diseño simple y es razonablemente fácil de diseñar, construir y modificar. Estos programas simples se volvieron bastante útiles y le ayudaron a las empresas a ahorrar grandes cantidades de dinero. En la actualidad, estos sistemas siguen disponibles pero su popularidad ha disminuido al pasar los años.
1980: Procesadores de lenguaje natural
Estas tecnologías hacen posible el entendimiento del lenguaje humano para las computadoras y las máquinas.
Se empezaron a diseñar para traducir el ruso al inglés para los estadounidenses al inicio de la década de los 60, pero no tuvieron el resultado esperado hasta 1980, cuando se aplicaron diferentes algoritmos y tecnologías computacionales para brindar una mejor experiencia.
1987-1993: Segundo invierno de IA
La Universidad Carnegie Mellon desarrolló el primer sistema comercial de Inteligencia Artificial llamado XCON. Se creó el lenguaje de programación LISP y se convirtió en el denominador común entre los desarrolladores de IA. Cientos de empresas invirtieron en este sistema ya que prometía millones en ganancias a quienes lo implementaran.
Pero en 1987, el mercado colapsó con el inicio de la era de las PCs debido a que esta tecnología opacaba a las costosas máquinas LISP. Ahora los dispositivos de Apple e IBM podían realizar más acciones que sus antecesores, lo cual los hacía la mejor opción en la industria.
1990: Agentes inteligentes
También conocidos como bots o asistentes virtuales digitales.
La creación e investigación de estos sistemas inició en 1990. Son capaces de interpretar y procesar la información que recibe de su entorno y actúa con base en los datos que recoge y analiza, para ser utilizados en servicios de noticias, navegación en sitios web, compras en línea y más.
Evolución de la Inteligencia Artificial: 2000 - 2023
6 INVENTOS QUE REVOLUCIONARON LA INTELIGENCIA ARTIFICIAL

2011: Asistentes virtuales
Un asistente virtual es una especie de agente de software que nos ofrece servicios que ayudan a automatizar y realizar tareas.
El asistente virtual más popular sin duda es Siri, creado por Apple en 2011. A partir del iPhone 4s está tecnología se integró en los dispositivos. Entendía lo que decías y respondía con una acción para ayudarte, ya sea buscando algo en internet, programando una alarma, un recordatorio o incluso decirte el clima.
2016: Sophia
Sophia fue creada en 2016 por David Hanson. Este androide es capaz de sostener conversaciones sencillas como los asistentes virtuales, pero a diferencia de ellos, Sophia hace gestos similares a los de las personas y genera conocimiento cada vez que interactua con una persona, posteriormente imitando sus acciones.
2018: BERT por Google
BERT, diseñado por Google en 2018, es una técnica de Machine Learning aplicada a procesadores de lenguaje natural, cuyo objetivo es entender mejor el lenguaje que usamos todos los días. Analiza todas las palabras que se usan en una búsqueda para entender la totalidad del contexto y arrojar resultados favorables para los usuarios.
Es un sistema que utiliza transformadores, una arquitectura de red neuronal que analiza todas las posibles relaciones entre las palabras que hay dentro de una oración.
2020: IA Autónoma
La firma norteamericana, Algotive, desarrolla algoritmos de Inteligencia Artificial Autónoma que elevan los sistemas de videovigilancia en industrias críticas.
Sus algoritmos se apoyan del Machine Learning, Internet de las Cosas (IoT) y algoritmos únicos de analítica de video para realizar acciones en específico dependiendo de la situación y lo que la organización requiera.
vehicleDRX, su solución para seguridad pública es un ejemplo de cómo los algoritmos de la organización vuelven inteligentes a las cámaras de videovigilancia para responder en situaciones de emergencia y ayudar a los oficiales a realizar mejor su trabajo.
Si te interesa saber más sobre las soluciones de Inteligencia Artificial Autónoma de Algotive visita: www.algotive.ai/vehicledrx
2022: GATO por Deep Mind
El nuevo sistema de Inteligencia Artificial credo por Deep Mind tiene la capacidad de completar más de 600 tareas diferentes de manera simultánea, desde redactar descripciones de imágenes hasta controlar un brazo robótico.
Actúa como un modelo de visión y de lenguaje que ha sido entrenado para ejecturar diferentes tareas con distintas modalidades y ser realizadas con éxito. Se espera que este sistema tenga un número mayor de acciones para realizarlas en un futuro y que abra paso a la Inteligencia General Artificial.
2022: vehicleDRX por Algotive
El novedoso software de Algotive, vehicleDRX tiene la capacidad de identificar y monitorear vehículos de interés y conducta sospechosa en motocicletas en tiempo real, analizando situaciones de riesgo en la calle y potencializando la infraestructura de videovigilancia del gobiernos estatales y agencias de seguridad.
vehicleDRX aumenta la seguridad pública y trabaja como un colaborador con los monitoristas de los centros de comando y agencias de seguridad pública gracias a sus algoritmos que le permiten realizar un análisis profundo, rastrear la velocidad y dirección del vehículo, vigilancia permanente, búsqueda de vehículos y motocicletas por características, crea expedientes del caso y es compatible con toda cámara IP.
Si te interesa saber más sobre las problemáticas que resuelve vehicleDRX ingresa a: www.algotive.ai/vehicledrx
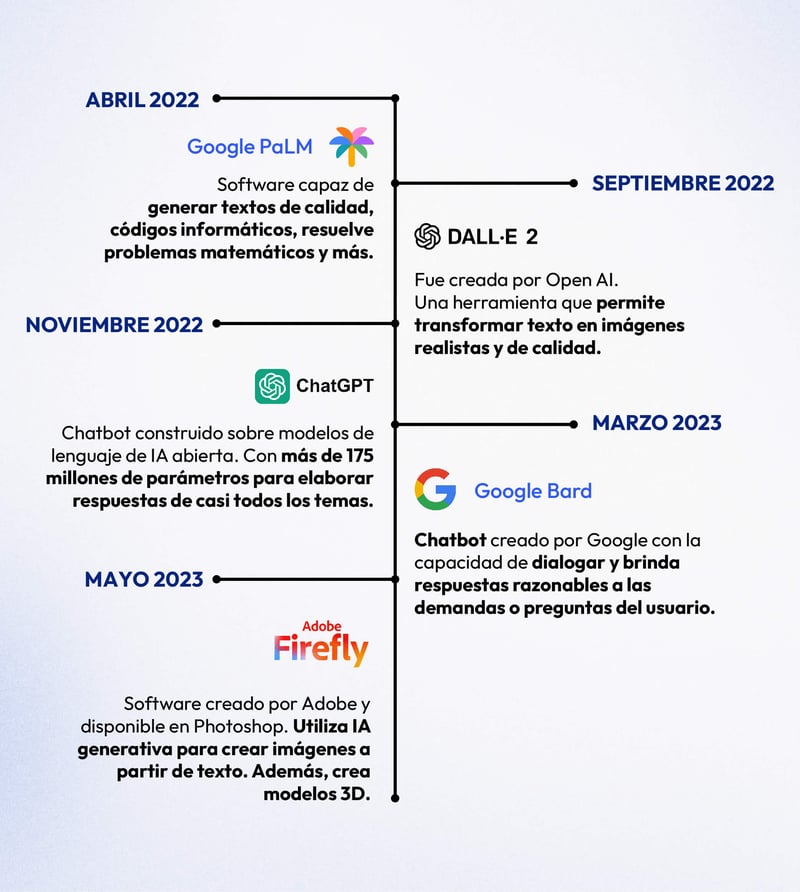
Abril de 2022

En los primeros meses de 2022, Google lanzó su IA llamada PaLM, o Pathways Language Model. Este software es capaz de generar textos de alta calidad, crear código informático, resolver problemas matemáticos complejos e incluso explicar chistes con eficacia y precisión.
En la entrada de su blog oficial: https://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html, Google demuestra cómo PaLM es capaz de hacer todo esto y otras cosas, por ejemplo, adivinar el título de una película a partir de sólo 3 emojis.
PaLM funciona recopilando información de 540 millones de parámetros y fue entrenado utilizando datos en varios idiomas y de diversas fuentes como documentos de alta calidad, libros, conversaciones reales y código de GitHube.
PaLM abrió el camino para uno de los desarrollos más recientes de Google en IA: "Bard", pero antes debemos abordar otras IA que se han hecho populares e incluso polémicas en el último año.
Septiembre de 2022

DALL-E 2 fue creada por Open AI como una versión actualizada de DALL-E, lanzada en enero de 2021. Esta segunda versión se hizo muy popular por su interfaz sencilla pero sus resultados complejos. Esta herramienta permite al usuario crear imágenes realistas de alta definición simplemente introduciendo texto en la interfaz de DALL-E 2.
Para que las imágenes sean lo más precisas posible, el usuario debe introducir descripciones detalladas y el programa generará el arte teniendo en cuenta esa información. Esta herramienta ha sido muy popular en los últimos meses, ya que ha permitido a todo tipo de personas crear imágenes de muy diversa índole y ha permitido a quienes no saben dibujar ni pintar expresarse a través de imágenes.
Noviembre de 2022

Otro popular y reciente desarrollo en IA, ChatGPT es un chatbot de IA construido sobre modelos de lenguaje de IA abierta, como GPT-4 y sus predecesores.
A través de una interfaz que se asemeja a una página de chat, GPT es capaz de entablar una conversación con el usuario. No sólo eso, sino que sus respuestas parecen animadas, ya que puede "admitir sus errores, debatir y rechazar peticiones inapropiadas", según su web oficial (https://openai.com/blog/chatgpt).
Esta IA se entrenó primero con el método Reinforcement Learning from Human Feedback (RLHF), en el que un entrenador humano proporcionaba conversaciones en las que actuaba como ambas partes: el ordenador y el entrevistador humano. ChatGPT tiene más de 175 millones de parámetros a partir de los cuales elabora sus respuestas y es capaz de hablar de casi cualquier tema. Personas de todo el mundo lo han utilizado para comprobar el alcance de sus capacidades.
Marzo de 2023

En respuesta a ChatGPT, Google lanzó su propio chatbot de IA, bautizándolo como Bard.
Está basado en LaMDA (Language Model for Dialogue Application), un modelo creado por Google. Bard puede dialogar con sus interlocutores y, según la compañía, puede ser utilizado como un colaborador creativo y útil, ya que puede ayudar al usuario a organizar y crear nuevas ideas que pueden ser utilizadas en varios entornos, desde el artístico hasta el lado corporativo de la vida.
Esta IA está en constante aprendizaje, ya que recoge patrones de billones de palabras que le ayudan a predecir cuál podría ser una respuesta razonable a las preguntas o demandas del usuario.
Mayo de 2023

Una de las últimas tendencias en IA popular, Firefly es un software creado por Adobe. De forma similar a DALL-E 2, Firefly utiliza la IA Generativa para crear imágenes a partir de texto, darle color a las imágenes, crear modelos 3D o extender imágenes más allá de sus bordes rellenando espacios en blanco.
Aunque puede utilizarse solo, Firefly también se ha introducido en el famoso programa de edición de imágenes Photoshop. Mediante la introducción de texto, Firefly puede añadir contenido a una imagen, eliminar elementos y sustituir partes enteras de una foto, entre otras cosas.
Historia del Machine Learning
MOMENTOS MÁS IMPORTANTES EN LA HISTORIA DEL MACHINE LEARNING

1952: Arthur Samuel crea el primer programa que juega damas chinas
Arthur Samuel es uno de los pioneros de los juegos de computadora y de la Inteligencia Artificial.
En 1952 comenzó a escribir el primer programa de ordenador basado en Machine Learning en el que pudo dar una demostración temprana de los conceptos fundamentales de la Inteligencia Artificial. El software era un programa que jugaba a las damas china y tenía la habilidad de mejorar su juego en cada partida. Fue capaz de competir con jugadores de nivel medio. Samuel siguió refinando el programa hasta poder competir con jugadores de alto nivel.
1957: Frank Rosenblatt diseñó Perceptron
Perceptron es un instrumento desarrollado por el psicólogo Frank Rosenbalatt para clasificar, explicar y modelar habilidades de reconocimiento de patrones en imágenes.
Fue el primer ordenador fabricado específicamente para crear redes neuronales. El Perceptron se implementó en uno de los ordenadores de IBM. Gracias a él fue capaz de ejecutar 40,000 instrucciones por segundo.
1963: Donald Michie construyó MENACE
MENACE era una computadora mecánica hecha de 304 cajas de fósforos diseñadas y construidas por Michie ya que no contaba con una computadora.
Michie construyó uno de los primeros programas con la capacidad de aprender a jugar Tic-Tac-Toe o gato. La nombró como Máquina Motor Educable de Ceros y Cruces (MENACE).
La máquina aprendió a jugar cada vez más partidas donde eliminaba una estrategia perdedora por parte del jugador humano en cada movimiento.
1967: Algoritmo del vecino más cercano
También conocido como k-NN, es uno de los algoritmos de clasificación más básicos y esenciales del Machine Learning.
Es un clasificador de aprendizaje supervisado que utiliza la proximidad para reconocer patrones, minería de datos y detección de intrusos a un punto de datos individual para clasificar el interés de los datos que lo rodean.
Se utiliza en la resolución de diversos problemas como sistemas de recomendación, búsqueda semántica y detección de anomalías.
1970: Seppo Linnainmaa y la diferenciación automática
Linnainmaa publicó en 1970 el modelo inverso de diferenciación automática. Este método se conoció más tarde como propagación hacia atrás y se usa para entrenar redes neuronales artificiales.
Es un conjunto de técnicas para evaluar el derivado de una función especificada por un ordenador en el que se ejecuta una secuencia de operaciones aritméticas elementales (suma, resta, división, etc.) y funciones elementales (exp, sin, log, cos, etc.) para aplicar la regla de la cadena haciendo cálculos automáticos.
1979: Hans Motavec creó el primer vehículo autónomo
Motavec construyó el Standford Cart en 1979. Constaba de 2 ruedas y una cámara de televisión que tenía movilidad de un lado a otro, sin necesidad de moverlo.
El Standford Cart fue el primer vehículo autónomo controlado por una computadora y capaz de esquivar obstáculos en un entorno controlado. En ese año, el vehículo cruzó con éxito una habitación llena de sillas sin la necesidad de intervención humana, en un periodo de 5 horas.
1981: Gerald Dejong y el concepto EBL
Dejong introdujo el concepto “Explanation based learning” (EBL) en 1981, un método de Machine Learning que hace generalizaciones o forma conceptos a partir de ejemplos de entrenamiento que le permiten descartar datos menos importantes o que no afecten a la investigación.
Está vinculado con la codificación para ayudar con el aprendizaje supervisado.
1985: Terry Sejnowski inventa NETtalk
NETtalk es una red neuronal artificial creada por Terry Sejnowski en 1986. Este software aprende a pronunciar palabras de la misma manera en que lo haría un niño.
El objetivo de NETtalk era construir modelos simplificados sobre la complejidad de aprender tareas cognitivas a nivel humano.
Este programa aprende a pronunciar texto escrito en inglés haciendo coincidir las transcripciones fonéticas para comparar.
1990: Kearns y Valiant plantearon Boosting
Es un meta-algoritmo de Machine Learning que reduce el sesgo y varianza en el aprendizaje supervisado para convertir un conjunto de clasificadores débiles a un clasificador fuerte.
Combina muchos modelos obtenidos mediante un método con poca capacidad predictiva con el objetivo de potencializarla.
La idea de Valiant y Kearns no se resolvió satisfactoriamente hasta que Freund y Schapire en 1996 presentaron el algoritmo AdBoost que fue un éxito.
1997: Jürgen Schmidhuber y Sepp Hochreiter crearon el Reconocimiento del discurso
Es parte del Deep Learning con una técnica llamada LSTM que utiliza modelos de redes neuronales donde puede aprender tareas hechas anteriormente.
Tiene la capacidad de recopilar datos como imágenes, palabras y sonidos donde los algoritmos lo interpretan y almacenan esta información para realizar acciones.
Es una técnica que con su evolución la hemos llegado a utilizar a diario en aplicaciones y dispositivos como Alexa de Amazon, Siri de Apple, Google Translate y más.
2002: Lanzamiento de Torch
Torch era una biblioteca de código abierto que proporcionaba un entorno de desarrollo numérico, Machine Learning y Computer Vision con un énfasis en particular en Deep Learning.
Era uno de los marcos más rápidos y flexibles para Machine y Deep Learning, el cual implementaron empresas como Facebook, Google, Twitter, NVIDIA, Intel y más.
Se ha dejó de desarrollar en 2017, pero sigue siendo utilizado para proyectos terminados e incluso desarrollos a través de PyTorch.
2006: Reconocimiento facial
Se evaluó el reconocimiento facial a través de análisis facial en 3D e imágenes con alta resolución.
Se realizaron diversos experimentos para reconocer individuos e identificar sus expresiones y género a partir del análisis de relevancia, incluso pudo reconocer gemelos idénticos gracias al análisis estratégico.
2006: El premio Netflix
Netflix creó este premio que consistía en que los participantes debían crear algoritmos de Machine Learning con la mayor eficacia para recomendar contenido y predecir calificaciones de los usuarios para películas, series y documentales.
El ganador recibiría un millón de dólares si lograba mejorar un 10% el algoritmo de recomendaciones de la organización, llamado Cinematch.
2009: Fei-Fei Li creó ImageNet
Fei-Fei inventó ImageNet que permitió avances importantes en el Deep Learning y el reconocimiento de imágenes, con una base de 140 millones de imágenes.
En la actualidad, consta de un conjunto de datos por excelencia para evaluar algoritmos de clasificación, localización y reconocimiento de imágenes.
En la actualidad ImageNet creó su propia competencia llamada ILSVRC que está diseñada para fomentar el desarrollo y evaluación comparativa de algoritmos de vanguardia.
2010: Kaggle, la comunidad para científicos de datos
Kaggle es una plataforma creada por Anthony Goldbloom y Ben Hamner. Es subsidiaria de Google y reúne a la comunidad de Data Science y Machine Learning más grande del mundo.
Esta plataforma tiene más de 540 mil miembros activos en 194 países donde los usuarios pueden encontrar recursos y herramientas importantes para realizar proyectos de Data Science.
2011: IBM y su sistema Watson
Watson es un sistema basado en Inteligencia Artificial que responde preguntas formuladas en lenguaje natural, desarrollado por la empresa IBM.
Esta herramienta cuenta con una base de datos construida a partir de numerosas fuentes como enciclopedias, artículos, diccionarios, obras literarias y más, además consulta fuentes externas para aumentar su capacidad de respuesta.
Este sistema venció a los campeones Rutter y Jennings en el programa de televisión Jeopardy!
2014: Facebook desarrolla Deep Face
En 2014, Facebook desarrolló un algoritmo de software que reconoce individuos en las fotos al mismo nivel que lo hacen los humanos llamado Deep Face.
Esta herramienta le permitió a Facebook identificar con una exactitud de 97.25% a las personas que aparecían en cada imagen, casi igualando la funcionalidad del ojo humano.
La red social decidió activar el reconocimiento de caras como forma de acelerar y facilitar el etiquetado de amigos en las fotos subidas por sus usuarios.
Historia del Deep Learning
MOMENTOS MÁS IMPORTANTES EN LA HISTORIA DEL DEEP LEARNING
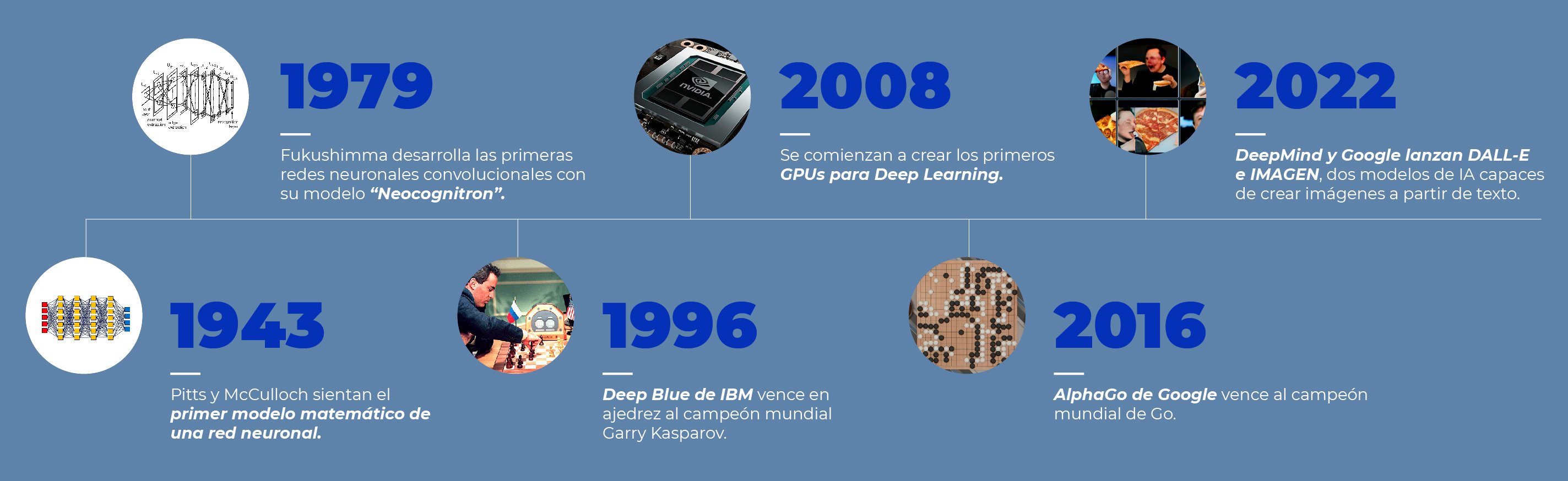
1943: Red neuronal de Pitts y McCulloch
El neurofisiólogo de la Universidad de Illinois, Warren McCulloch, y el psicólogo cognitivo, Walter Pitts, publicaron “A Logical Calculus of the ideas Imminent in Nervous Activity” en 1943, en el que describen la neurona “McCulloch - Pitts”, el primer modelo matemático de una red neuronal.
El trabajo de ambos ayuda a describir las funciones del cerebro y demostrar el poder computacional que podían tener elementos conectados en una red neuronal. Con esto, se sentaron las bases teóricas para las redes neuronales artificiales que se usan hoy.
1960: Henry J. Kelley inventa el Modelo de propagación hacia atrás
En su trabajo “Gradient Theory of Optimal Flight Paths”, Henry J. Kelley muestra la primera versión de un Modelo de propagación hacia atrás continuo. Es la esencia del entrenamiento de redes neuronales, con el cual ser pueden refinar los modelos de Deep Learning.
A través de este modelo, se pueden ajustar los pesos de una red neuronal basados en la tasa de error obtenida de intentos previos.
1979: Fukushimma diseña las primeras redes neuronales convolucionales con Neocognitron
En 1979, Kunihiko Fukushima diseño por primera vez las redes neuronales convolucionales con múltiples capas, desarrollando una red neuronal artificial llamada Neocognitron.
Este diseño le permitía a la computadora reconocer patrones visuales. También permitía incrementar el peso de ciertas conexiones en las características más importantes. Muchos de sus conceptos siguen siendo usados hoy en día.
1982: Se inventa Red de Hopefield
John Hopefield crea la primera red neuronal recurrente, a la cual llama red de Hopefield. La principal innovación de esta red es su sistema de memoria que ayudará a varios modelos de RNR en la era moderna del Deep Learning.
Hopefield buscaba que su red neuronal artificial almacenara y recordara información como el cerebro humano. A partir del reconocimiento de patrones puede detectar errores en la información e incluso reconocer cuando la información no corresponde con lo que se busca lograr.
1986: Se crea el procesamiento distribuido en paralelo
En 1986, Rumelhart, Hinton y McClelland popularizaron este concepto, gracias a la implementación exitosa del modelo de propagación hacia atrás en una red neuronal.
Este fue un gran paso dentro del mundo del Deep Learning ya que permitió entrenar redes neuronales más complejas, lo cual era uno de los obstáculos más grandes en esta área. Los tres principios fundamentales del procesamiento distribuido en paralelo son la distribución de la representación de la información, la memoria y el conocimiento se almacenan dentro de las conexiones entre neuronas y el aprendizaje ocurre gracias a que la fortaleza de la relación cambia a través de las experiencias.
1989: Yann LeCun demuestra de manera práctica el modelo de propagación para atrás
Uno de los más grandes exponentes de las posibilidades del Deep Learning, Yann LeCun combinó las redes neuronales convolucionales con la propagación hacia atrás para enseñarle a una máquina a leer dígitos escritos a mano.
Enseñó su trabajo y los resultados del mismo en Bell Labs, siendo la primera vez que se demostraba un modelo así frente al público. Ver aquí.
1997: Deep Blue de IBM vence a Garry Kasparov
Garry Kasparov, campeón mundial de ajedrez, fue vencido por el superordenador construido por IBM Deep Blue el 11 de mayo de 1997.
Deep Blue venció dos partidas, empató tres y perdió una, lo cual convertía a esta computadora en la primera campeona virtual del mundo de ajedrez.
1999: Nvidia crea el primer GPU
Geforce 256 fue el primer GPU de la historia, creado en 1999 por Nvidia. Esta tecnología liberaría posibilidades que antes solo eran posibles en teoría. Muchos de los avances en el ramo del Deep Learning y la Inteligencia Artificial pudieron realizarse gracias a este componente tecnológico.
2006: Se crean las redes de creencia profunda
En su trabajo “A fast learning algorithm for deep belief nets” Geoffrey Hinton, Ruslan Salakhutdinov, Osindero y Teh demostraron la creación de una nueva red neuronal llamada la Red de creencia profunda. Este tipo de red neuronal hizo que el proceso de entrenamiento con grandes cantidades de datos fuera más sencillo.
2008: GPU para Deep Learning
10 años después del primer GPU creado por Nvidia, el grupo de. Andrew NG en Stanford empezaron a promocionar el uso de GPUs especializados para Deep Learning. Esto les permitiría entrenar las redes neuronales de manera más rápida y eficaz.
2012: El experimento del gato de Google
Google mostró más de 10 millones de videos aleatorios de YouTube a un cerebro y después de mostrarle más de 20,000 distintos objetos, comenzó a reconocer imágenes de gatos usando algoritmos de Deep Learning, sin que se le indicara las propiedades o características de los mismos. Esto abrió una nueva puerta en el aprendizaje automático y profundo puesto que probaba que no se necesitaban etiquetar imágenes para que un modelo reconociera la información presentada.
2014: Se crean las redes neuronales generativas adversarias
Ian Goodfellow crea las redes neuronales generativas adversarias lo cual abre una nueva puerta en los avances tecnológicos dentro de áreas tan diferentes como las artes y las ciencias, gracias a su habilidad de sintetizar datos reales.
La manera en que funciona es que dos redes neuronales compiten entre sí en un juego, y a través de esta técnica puede aprender a generar nuevos datos con las mismas estadísticas que el conjunto de entrenamiento.
2016: AlphaGo vence al campeón mundial de Go
El modelo de aprendizaje profundo por refuerzo de Deepmind vence al campeón humano en el complejo juego del Go. El juego es mucho más complejo que el ajedrez, por lo que esta hazaña capta la imaginación de todos y lleva la promesa del aprendizaje profundo a un nivel completamente nuevo.
2020: AlphaFold 2020
AlphaFold es un sistema de IA desarrollado por DeepMind que predice la estructura 3D de una proteína a partir de su secuencia de aminoácidos. Regularmente alcanza una precisión que compite con la de los experimentos.
DeepMind y el Instituto Europeo de Bioinformática del EMBL (EMBL-EBI) se han asociado para crear la base de datos AlphaFold y poner estas predicciones a disposición de la comunidad científica. La base de datos cubre el proteoma humano completo (incluidos los fragmentos de proteínas largas) y los proteomas de otros 47 organismos clave (por ejemplo, el ratón), así como la mayoría de las entradas de UniProt curadas manualmente (Swiss-Prot).
2022: IMAGEN y Dall-E mini
En este año, Google y Deepmind lanzan sus dos modelos que pueden crear imágenes originales a partir de líneas de texto alimentadas por los usuarios.
Este es uno de los pasos más importantes dentro de la industria de la IA, ya que permite por primera vez demostrar la capacidad creativa de estas tecnologías y las fronteras que podríamos alcanzar cuando los humanos trabajen de manera colaborativa con las máquinas.
Si quieres conocer más de cómo funciona la Inteligencia Artificial Autónoma, no olvides visitar nuestra guía completa aquí.
Y si te interesa saber más sobre Machine Learning y su impacto puedes leer nuestro artículo sobre el tema aquí y también puedes aprender todo sobre Deep Learning aquí.